
Executive summary
Enterprise AI programs are moving from isolated copilots to agentic systems that combine large language models with retrieval, tools, APIs, memory, and increasingly autonomous decision loops. That architectural shift matters because it expands the attack surface beyond the model itself: the risk now sits in the entire system, especially where an agent can read untrusted content, invoke tools, access enterprise systems, or retain information across sessions. Recent academic work on agentic AI, MITRE’s OpenClaw investigation, Microsoft’s 2026 AutoJack research, and the 2024–2026 guidance coming from NIST, ISO, major cloud providers, and national cyber agencies all converge on the same conclusion: the practical problem is no longer “Is the model safe?” but “Can the whole agentic workflow be trusted under adversarial conditions?”
For CIOs, CISOs, and security leaders, the core governance challenge is straightforward to state but hard to solve: AI agents function like high-speed, semi-autonomous digital workers. If they are over-privileged, grounded on poisoned data, manipulated through prompt injection, or allowed to execute unreviewed actions, they can become confused deputies that transgress policy at machine speed. The UK NCSC has explicitly warned that prompt injection should not be treated as a simple SQL-injection analogue and has argued that resilience and impact reduction—not a fantasy of perfect prevention—should be the design goal. OWASP’s 2025 LLM Top 10 similarly places prompt injection at the top of the modern GenAI risk stack.
This report assumes no specific enterprise size or industry. The recommendations are therefore designed to be sector-agnostic and should be tuned to the sensitivity of the data, the criticality of the connected systems, and the consequences of autonomous failure in your environment. In practice, the most defensible baseline is a layered program built around Zero Trust, identity-centric agent governance, least privilege, RAG hardening, runtime guardrails and AI firewalls, human approval for consequential actions, observability, memory controls, formal governance, and compliance alignment using frameworks such as the NIST AI RMF, NIST’s Generative AI Profile, ISO/IEC 42001, ISO/IEC 23894, and existing ISMS controls such as ISO/IEC 27001.
The practical takeaway is this: enterprises should treat AI agents as a new class of non-human identity with delegated authority, place all agent traffic behind a policy-enforcing control plane, and instrument the full workflow—from prompt entry to model call to tool invocation to downstream side effect—so that risky actions can be blocked, approved, traced, and audited. That is the foundation for safe scale.
Problem statement and risk landscape
Enterprise adoption is accelerating faster than many governance programs. Deloitte’s 2026 reporting indicates that agentic AI usage is scaling quickly and that 74% of respondent organizations expect at least moderate AI-agent use by 2027. Google Cloud’s 2026 agent trends research likewise describes an “agent leap” in which enterprises move from isolated prompts to semi-autonomous workflow orchestration. That combination of higher autonomy and higher integration raises both the probability and the blast radius of failure.
The risk landscape is no longer theoretical. A NeurIPS 2024 benchmark, AgentDojo, showed that AI agents using external tools over untrusted data are vulnerable to prompt injection, and the benchmark was constructed with 97 realistic tasks and 629 security test cases. MITRE’s 2026 OpenClaw investigation mapped practical attack paths involving direct and indirect prompt injection, AI-agent tool invocation, and agentic configuration modification. In June 2026, Microsoft’s AutoJack research showed how a single malicious webpage could turn a browsing agent into a remote code execution vector by exploiting insecure localhost trust assumptions and unauthenticated control channels. The message for enterprise security is clear: agent risk now includes web-to-agent, tool-to-agent, data-to-agent, and control-plane attack paths.
At the standards layer, NIST’s Generative AI Profile extends the NIST AI RMF to generative AI risks and connects those risks to the framework’s Govern, Map, Measure, and Manage functions. ISO/IEC 42001 provides the first AI management system standard, while ISO/IEC 23894 offers AI-specific risk management guidance. Together, these sources establish that AI risk management is not just a model-science issue; it is an enterprise management system problem spanning governance, operations, security, and assurance.

One important strategic nuance deserves emphasis. Recent official guidance increasingly treats advanced agents as a form of insider-risk problem. Google DeepMind’s June 2026 AI Control Roadmap explicitly advocates defense-in-depth guardrails to catch potentially adversarial or misaligned agent behavior even when alignment alone is insufficient. That mirrors the posture long taken in identity security: assume some privileged actors—human or non-human—will eventually behave unexpectedly, and architect for containment, detection, and rapid intervention.
Attack surface analysis
The modern enterprise AI agent should be analyzed as a stack of interconnected trust boundaries, not as a single model endpoint. The clearest treatment of this comes from recent agent-security literature, which emphasizes that tools, retrieval, memory, and autonomy markedly enlarge the attack surface.
| Layer | Principal Threats | Why It Matters | High-Priority Controls |
|---|---|---|---|
| UI and User Workflow | Direct prompt injection, auth/session abuse, unsafe approval UX | User-facing surfaces are the first trust boundary, and browsing or desktop flows can bridge into powerful local or enterprise control planes. | Strong auth, session scoping, trusted approval patterns, content sanitization, replay protection |
| Prompt Framework | System-prompt override, instruction confusion, jailbreaks | LLM systems do not cleanly separate instructions from data, which is why prompt injection behaves differently from classic injection classes. | Prompt templating, role separation, minimization of latent instructions, adversarial testing |
| LLM Runtime | Unsafe outputs, hallucination, insecure output handling | Insecure downstream use of model output can translate text mistakes into security failures or code execution. | Output validation, tool-call schema enforcement, constrained decoding where possible, evals |
| Memory | Cross-session leakage, retention of sensitive data, poisoning of long-term context | Persistent memory makes agents more useful, but it also creates a new high-value data store and a mechanism for long-lived manipulation. | TTLs, encryption, minimization, memory write policies, purge APIs, access reviews |
| Tools and Tool Responses | Tool hijacking, over-broad actions, malicious tool output | Agent frameworks are especially exposed when untrusted tool output re-enters model context or when agent decisions trigger high-impact side effects. | Tool allowlists, typed arguments, transaction limits, sandboxing, human approval for side effects |
| APIs and Control Plane | MCP abuse, token theft, localhost trust flaws, weak broker controls | Control planes concentrate authority; a small design flaw here can bypass many application-layer safeguards. | mTLS, DPoP/token binding, gateway mediation, short-lived tokens, signed requests |
| Enterprise Systems | Privilege escalation, lateral movement, unauthorized changes | Once agents connect to ERP, CRM, ITSM, IAM, or cloud control planes, blast radius grows from “bad answer” to “business disruption.” | RBAC/ABAC, least privilege, action budgets, break-glass control, segregation of duties |
| Data Sources and RAG | Retrieval poisoning, hidden instructions in documents/web pages, data exfiltration | Third-party or untrusted content can hijack the agent or bias retrieval-driven decisions. | Provenance checks, access-aware indexing, document screening, grounding checks, source trust scoring |
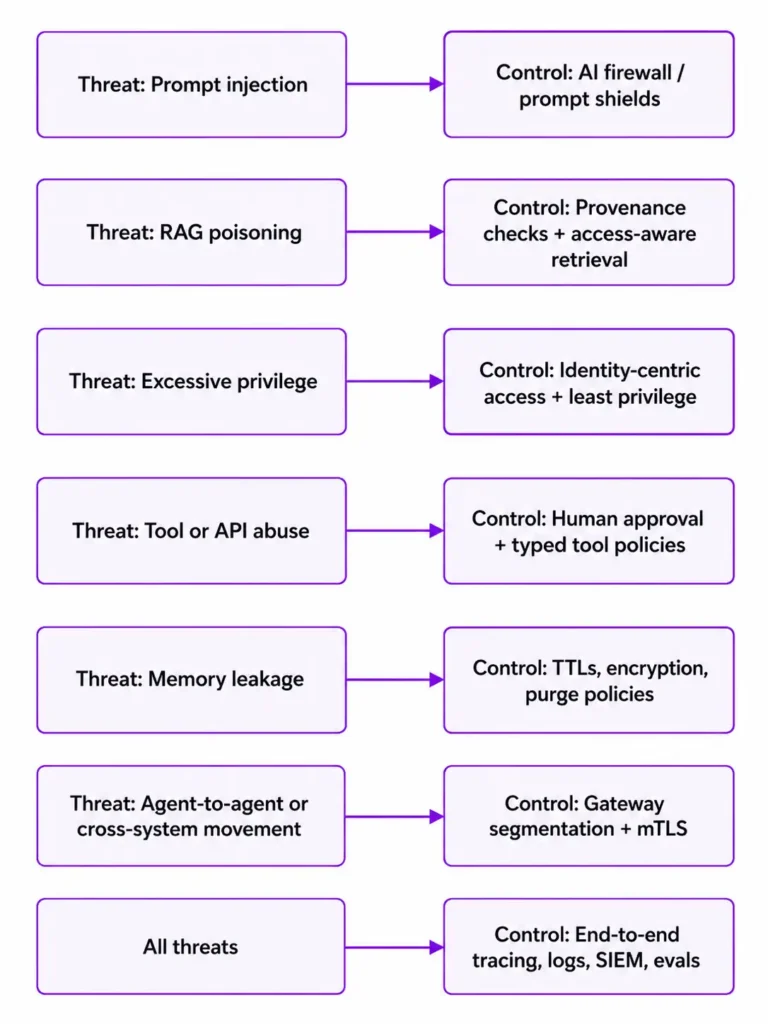
The most important design implication is that the model is rarely the only—or even the main—problem. In enterprise deployments, the highest-risk failures usually arise where the agent crosses boundaries: from untrusted content into reasoning, from reasoning into tools, from tools into enterprise APIs, and from one session into persistent memory. That is why system-level controls matter more than purely model-level tuning.
Priority controls and target architecture
The most defensible enterprise pattern is to implement controls in a strict order of dependency. Start with identity and policy, then constrain connectivity and action, then add runtime inspection, then formalize monitoring and governance. NIST’s AI RMF and Playbook are helpful here because they reinforce an operational sequence: govern first, map the system, measure the risks, and only then manage them continuously. ISO/IEC 42001 complements this by requiring an AI management system capable of continual improvement and alignment with other management standards, including security and privacy.
A practical priority stack for most enterprises is as follows. First, put every agent behind a unique identity and register it as an inventory item with an accountable owner. Second, enforce least privilege at runtime so the agent gets only the narrowest permissions required for the specific task. Third, harden retrieval and memory so the agent cannot read or retain more than it should. Fourth, deploy a runtime guardrail layer—AI firewall, prompt shield, or equivalent—to inspect prompts, tool responses, and model outputs. Fifth, require human approval for consequential actions. Sixth, instrument end-to-end traces, metrics, and security telemetry. Seventh, operationalize all of this under a governance program mapped to NIST and ISO controls.
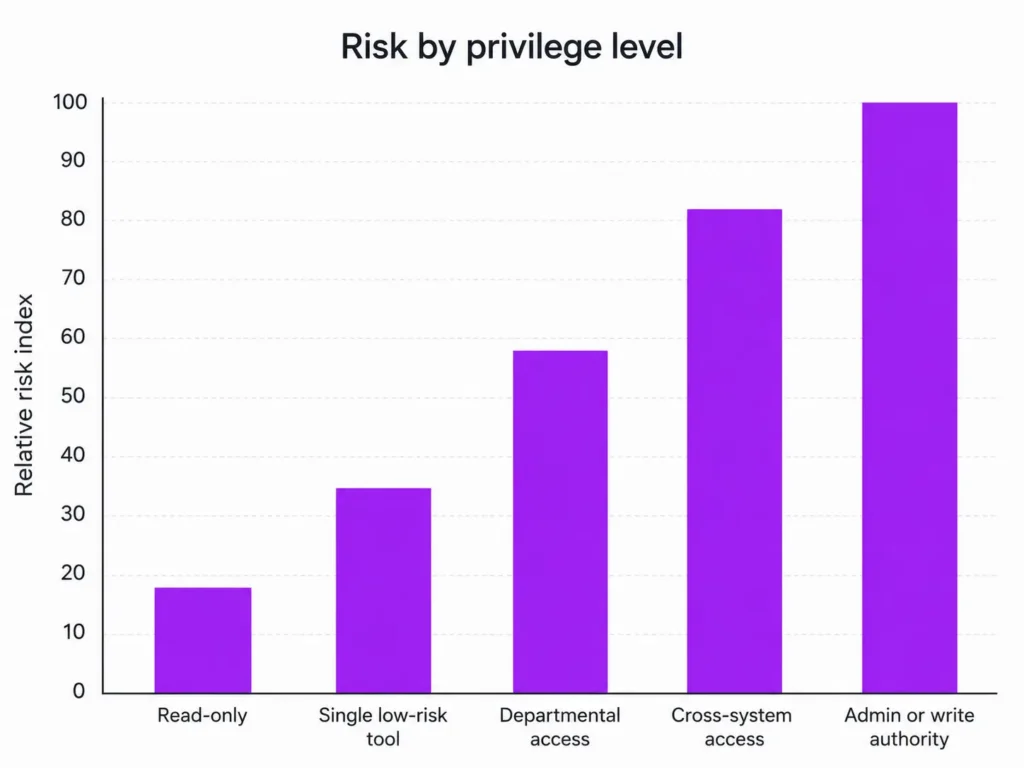
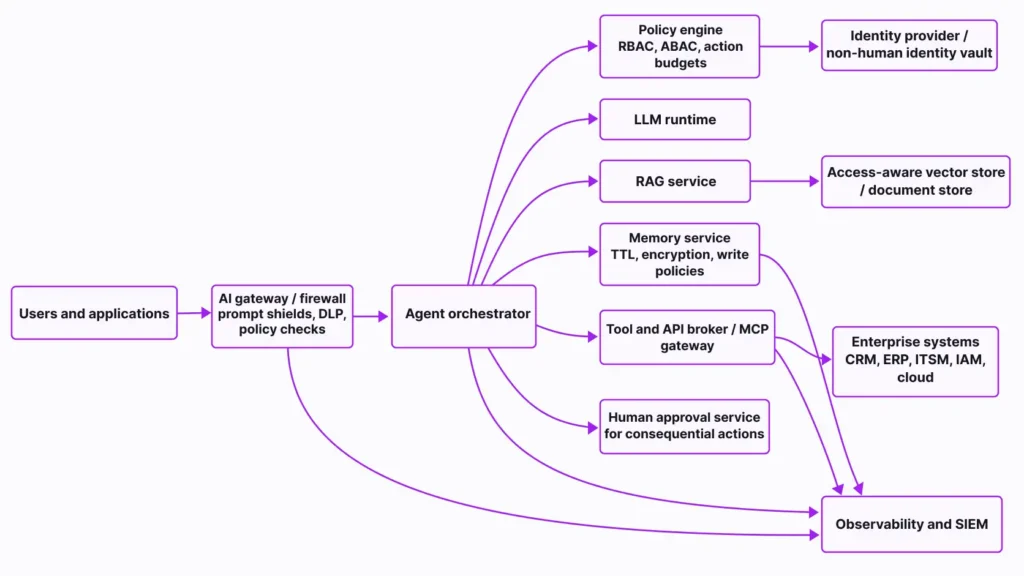
A concise implementation checklist should include the following: register agents and tool integrations in an authoritative inventory; classify each agent by data sensitivity and action criticality; issue unique non-human identities and short-lived credentials; define allowlisted tools and typed tool schemas; separate read-only from write-capable actions; require approval for payments, record deletion, IAM changes, and external communications; enforce access-aware RAG with source screening; limit memory writes and retention periods; stream traces and policy events to SIEM; run red-team tests before release; and map all controls to NIST AI RMF, ISO/IEC 42001, and your existing internal security control library.
Maturity, metrics, and vendor options
A mature AI-agent security program is not binary. It develops through stages: ad hoc, pilot, governed, scaled, and optimized. In the ad hoc stage, security is mostly reactive and agent access is opaque. In the governed stage, the organization has explicit ownership, role-based access, control-plane enforcement, and logging. At scale, the enterprise adds policy-as-code, attack simulation, continuous evaluations, and measurable service-level objectives for safety and control effectiveness. This progression aligns well with the “continual improvement” logic embedded in ISO/IEC 42001 and the Govern-Map-Measure-Manage motion of the NIST AI RMF.
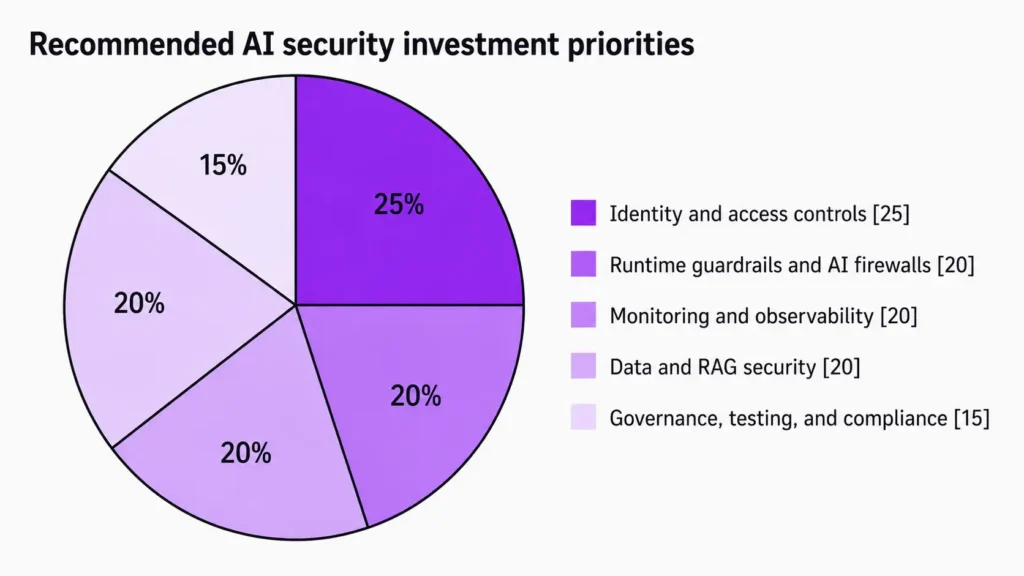
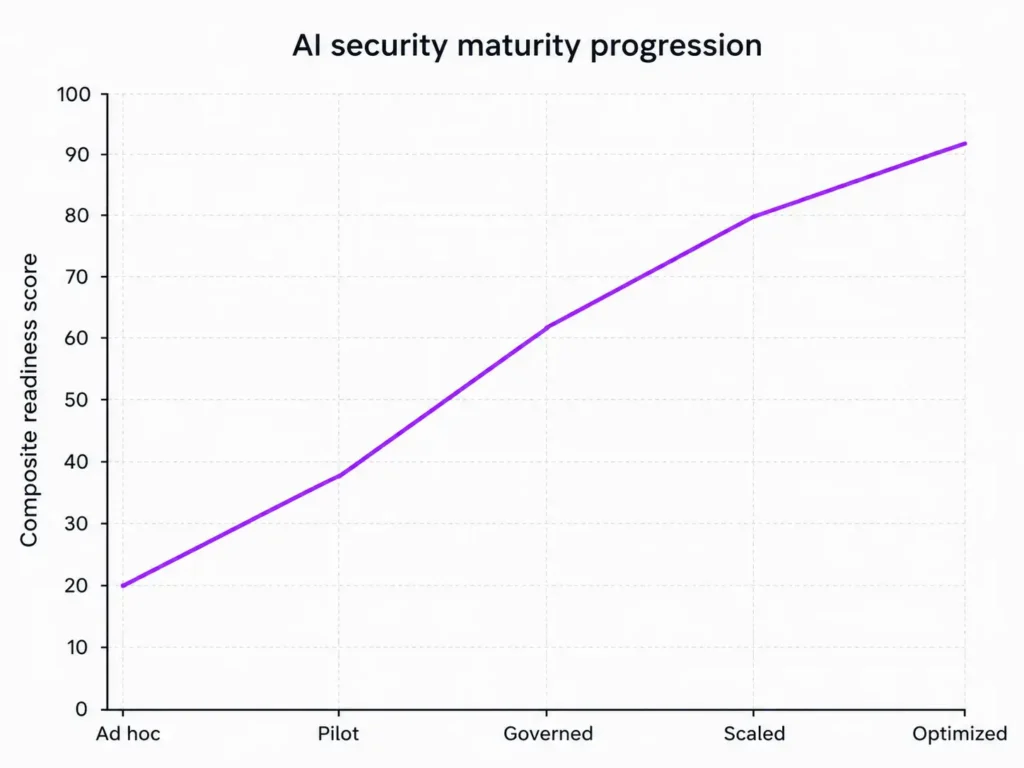
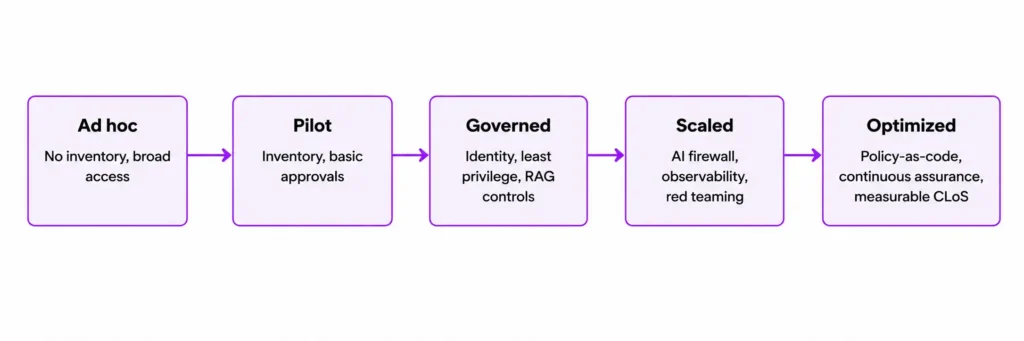
A practical dashboard should measure both security posture and operational effectiveness. Major cloud providers now expose observability for agent sessions, turns, traces, logs, and runtime metrics, while OpenAI and other vendors increasingly emphasize trace-based debugging and human-review interruption points. That means security teams can move beyond simple “blocked prompts” counts and toward workflow-level assurance.
| Dashboard Item | Why It Matters | Example Target or Alert |
|---|---|---|
| Prompt-injection Detection Rate | Tracks exposure at the system boundary | Alert on spikes by source, tool, or document class |
| Blocked High-risk Tool Calls | Shows whether guards are preventing unsafe side effects | Investigate repeated attempts against the same workflow |
| Agent Privilege Scope by Tier | Reveals over-privileged agents | Reduce exception count quarter over quarter |
| Approval Bypass Attempts | Detects attempts to evade human review | Immediate incident review |
| Sensitive-data Leakage Findings | Measures DLP effectiveness | Zero tolerance for regulated data exfiltration |
| RAG Provenance Failures | Indicates poisoning or weak source controls | Block unknown or low-trust sources by default |
| Memory Retention Violations | Detects policy drift in long-term context storage | Expire or purge on violation |
| Trace Completeness | Ensures every run is auditable | Target near-total coverage for production agents |
| Mean Time to Disable an Agent | Tests operational containment | Keep emergency disable capability measured and exercised |
| Red-team Pass Rate / Eval Score | Quantifies readiness before promotion | Gate production on minimum threshold |
Vendor comparison
The market now splits into two broad categories: cloud-native control stacks that bundle guardrails into the agent platform, and specialized AI security vendors that emphasize lifecycle scanning, runtime defense, posture management, discovery, and red teaming. As of June 23, 2026, public pricing is mixed: cloud vendors generally expose usage-based pricing pages, while specialized vendors more often use contact-sales or credit-based models.
| Vendor | Product | Key Features | Deployment Model | Pros | Cons | Pricing Model |
|---|---|---|---|---|---|---|
| Cloud / Hyperscaler Platforms | ||||||
| AWS | Amazon Bedrock Guardrails + AgentCore | Content and privacy guardrails, agent observability, managed runtime and memory, agent builder integration | Managed cloud service | Tight AWS integration; documented observability and guardrails; broad enterprise fit | Best fit if core workloads already sit in AWS; multi-cloud governance may require extra tooling | Public usage-based pricing via AWS pricing pages |
| Microsoft Azure | Azure AI Content Safety / Prompt Shields / Foundry controls | Prompt-shield detection for user and document attacks, content safety, agent controls in Foundry | Managed cloud service | Mature enterprise identity ecosystem; direct support for prompt/document attack detection | Pricing/details can span multiple Azure services; architecture can be complex in mixed stacks | Public pay-as-you-go pricing pages for Content Safety / Foundry |
| Google Cloud | Gemini Enterprise Agent Platform + Agent Gateway + Model Armor | Agent platform, gateway mediation, mTLS and DPoP-aware controls, observability, prompt-injection and sensitive-data protection | Managed cloud service | Strong agent connectivity governance; explicit MCP security posture; rich observability | Newer platform surface may require process adaptation; best value when using Google control plane broadly | Public pricing for agent platform; Model Armor offers free tier plus usage/contact-sales elements |
| AI Security Platforms | ||||||
| Palo Alto Networks | Prisma AIRS | Centralized AI control plane, runtime firewall, agent discovery, identity verification, policy enforcement, model security | SaaS / enterprise platform | Broad enterprise-security orientation; lifecycle plus runtime focus | Typically a larger-platform buy; may exceed needs for smaller programs | Public documentation describes Software NGFW credits and token-based usage for parts of AIRS |
| Lakera | Lakera Guard / Check Point AI Security docs | Prompt-defense focus, real-time screening, governance for agent interactions | API / SaaS | Strong specialization in injection and runtime protection | Less of a full-stack cloud platform; broader lifecycle features may require pairing | Public pricing portal exists, but enterprise terms are not broadly detailed in public docs |
| Protect AI | Guardian / Layer / LLM Guard | Model scanning, runtime threat detection for RAG and agents, AI firewall patterns, red teaming | SaaS, on-prem, distributed scanning options | Strong lifecycle coverage, including model supply-chain concerns | Product set may require more integration design than bundled cloud offerings | Mixed: some open-source/free components, commercial platform typically contact-sales |
| HiddenLayer | HiddenLayer Platform / AI Runtime Security | AI discovery, runtime security, supply-chain protection, attack simulation | SaaS / platform | Strong focus on AI-specific detection and simulation | Public pricing is limited; may require complementary governance tooling | Public pricing not broadly disclosed; generally contact-sales |
Ninety-day roadmap and next steps
A sensible 90-day implementation plan should prioritize control points that reduce blast radius fastest. The first month is about visibility and containment. The second month is about runtime enforcement. The third month is about evidence, assurance, and governance. That sequencing aligns with both NIST’s operating model and the security realities surfaced by current agent incidents.
Days 1–30: establish foundations. Build an inventory of all agents, connectors, tools, MCP servers, third-party models, vector stores, and long-term memory components. Assign an owner to each agent. Classify every agent by data sensitivity, action criticality, and external connectivity. Register each one as a non-human identity. Eliminate shared credentials. Set default-deny tool access and immediately separate read-only capabilities from write-capable ones. For any agent connected to finance, IAM, cloud administration, code deployment, or regulated records, place a manual approval gate in front of side effects.
Days 31–60: deploy technical controls. Put prompt and response traffic through an AI firewall or equivalent shield. Screen documents and tool responses for indirect prompt injection. Rebuild RAG pipelines so indexing and retrieval respect existing entitlements. Add provenance or trust scoring to high-value sources. Lock down memory: define retention times, turn off unnecessary long-term memory, and implement purge flows. Make sure all agent-to-tool and agent-to-agent traffic goes through a broker or gateway with policy enforcement, short-lived credentials, and cryptographic protections such as mTLS where the platform supports it.
Days 61–90: operationalize governance and assurance. Turn on end-to-end traces, logs, and alerting for prompt events, tool calls, approvals, failures, and policy violations. Define release gates using evaluations and red-team scenarios, especially for prompt injection, data exfiltration, tool abuse, and unsafe approvals. Map the implementation to NIST AI RMF functions and your ISO/ISMS control environment. Establish executive metrics: percentage of agents inventoried, percentage with unique identities, percentage with approval control for high-risk actions, percentage of runs traceable, and time to isolate or disable an agent. Finally, run at least one tabletop exercise involving an injected prompt, a compromised tool response, and a forced agent shutdown.
A concise 90-day checklist for CIO/CISO review is below.
| Control Objective | By Day 30 | By Day 60 | By Day 90 |
|---|---|---|---|
| Agent Inventory and Ownership | Complete initial inventory | Maintain change process | Audit completeness monthly |
| Identity and Secret Hygiene | Remove shared credentials | Enforce short-lived credentials | Review all privileged exceptions |
| Least Privilege | Read/write separation in place | Tool allowlists enforced | Privilege attestations completed |
| RAG and Data Security | Identify sensitive sources | Access-aware retrieval enabled | Provenance and screening measurable |
| Runtime Guardrails | Select platform | Enable prompt/response screening | Tune with incident learnings |
| Human Review | Define high-risk actions | Approval workflow active | Measure bypass attempts and latency |
| Observability | Core logs and traces on | Dashboards operational | SIEM alerts and runbooks tested |
| Governance and Compliance | Draft policy and risk taxonomy | Map to NIST / ISO controls | Executive review and sign-off |
The enduring strategic point is that enterprise AI security is becoming identity- and control-plane-centric. The most successful programs will not be the ones with the most elaborate prompts; they will be the ones that treat AI agents like privileged software principals, constrain them with policy, verify them continuously, and preserve the ability to stop them safely when reality departs from intent. That is the operating model that best fits the current evidence from NIST, ISO, academia, national cyber guidance, cloud-provider architectures, and 2026 real-world agent exploit research.


